此篇是參考 Referenece 1 & 2 的內容,並實際操作之後的心得分享。
Databricks Workflows 是一個可以用來建立 data processing, machine learning, and analytics pipelines 的服務。Workflows 有完整的 managed orchestration services,包含 Databricks Jobs 以及 Delta Live Tables。Databricks Jobs 可以用來執行 non-interactive code,而 Delta Live Tables 則是用來建立 ETL pipelines。
執行一個 Delta Live Tables pipeline,從 cloud storage 中讀取 raw clickstream data,並且清理、準備資料,將資料 sessionize,最後將 sessionized data 寫入 Delta Lake。
執行一個 Delta Live Tables pipeline,從 cloud storage 中讀取 order data,並且清理、轉換資料,最後將資料寫入 Delta Lake。
將 order data 與 sessionized clickstream data 做 join,建立一個新的資料集。
從準備好的資料中,提取 features。
平行處理多個 Taks,將 features 寫入 Delta Lake,並且訓練一個 machine learning model。
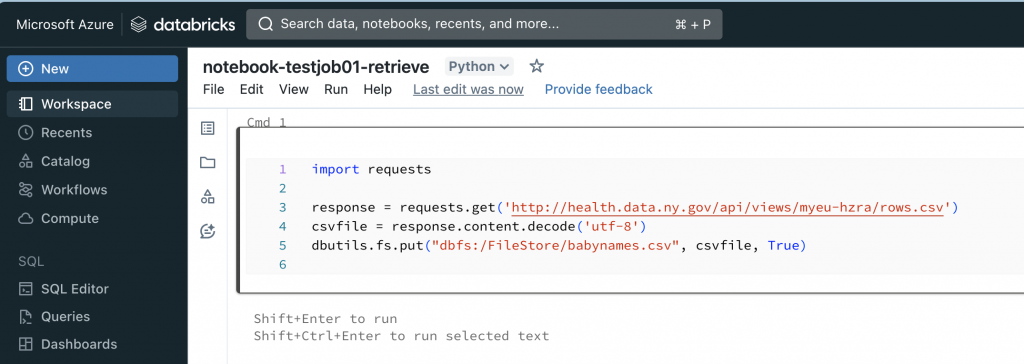
1.1. Reretive and save data
import requests
response = requests.get('http://health.data.ny.gov/api/views/myeu-hzra/rows.csv')
csvfile = response.content.decode('utf-8')
dbutils.fs.put("dbfs:/FileStore/babynames.csv", csvfile, True)
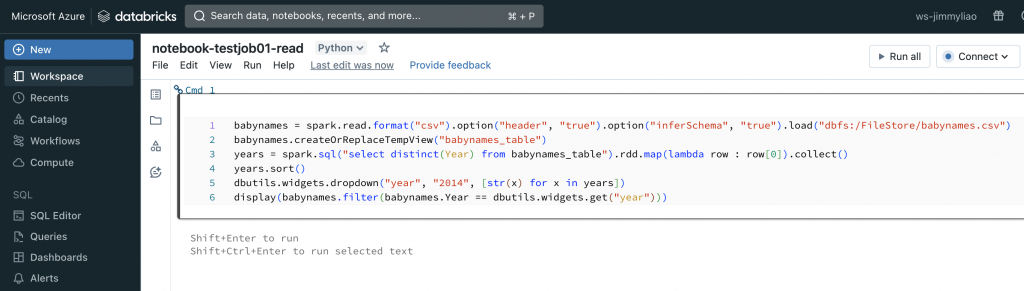
1.2. Read and display filtered data
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("dbfs:/FileStore/babynames.csv")
babynames.createOrReplaceTempView("babynames_table")
years = spark.sql("select distinct(Year) from babynames_table").rdd.map(lambda row : row[0]).collect()
years.sort()
dbutils.widgets.dropdown("year", "2014", [str(x) for x in years])
display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
將這個資料集儲存到 DBFS。
建立一個新的 notebook,並且加入程式碼來從 DBFS 讀取資料集,並且依照年份來過濾資料,最後顯示結果。
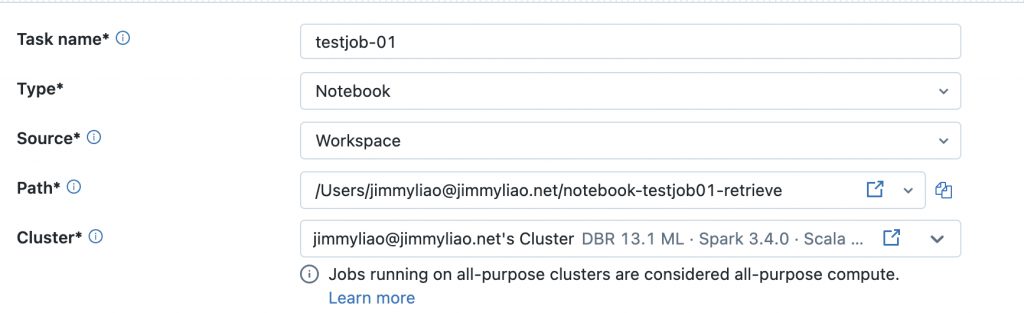
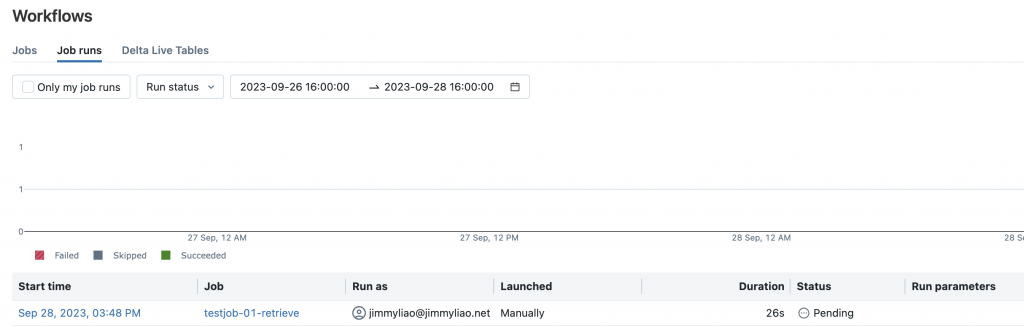
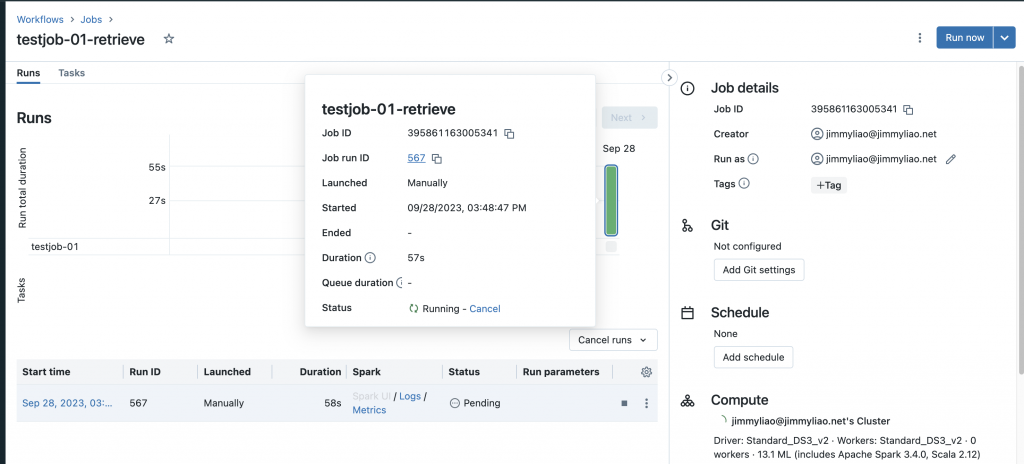
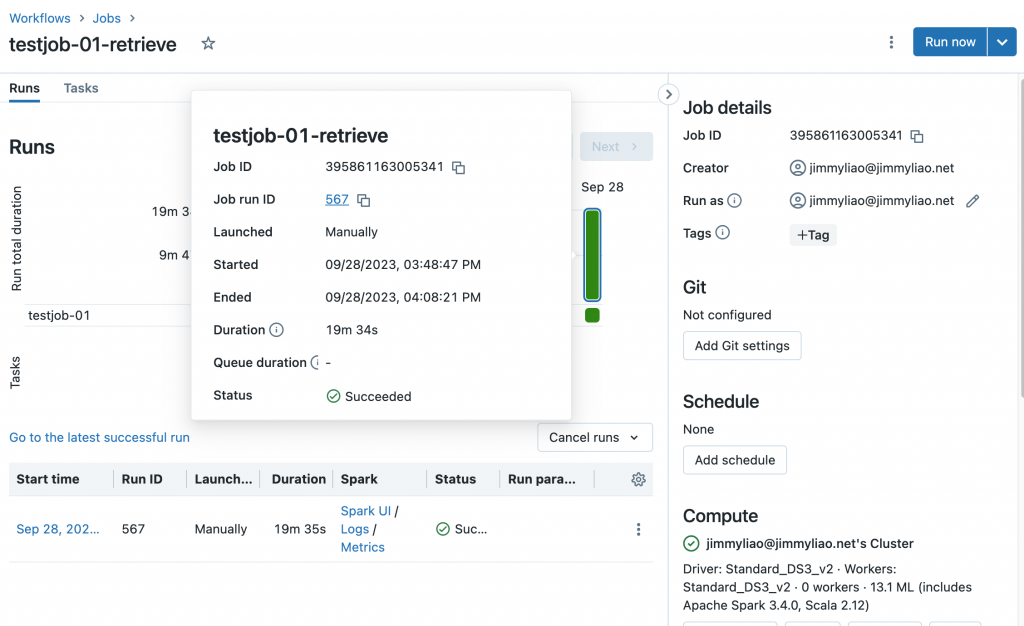
建立一個新的 job,並且使用這兩個 notebook 來設定兩個 tasks。
執行這個 job,並且檢視結果。

Reference:


 iThome鐵人賽
iThome鐵人賽